Episode Summary: This 86th episode of Learning Machines 101 discusses the problem of assigning probabilities to a possibly infinite set of outcomes in a space-time continuum which characterizes our physical world. Such a set is called an “environmental event”. The machine learning algorithm uses information about the frequency of environmental events to support learning. If we want to… Read More »
This 85th episode of Learning Machines 101 discusses formal convergence guarantees for a broad class of machine learning algorithms designed to minimize smooth non-convex objective functions using batch learning methods. In particular, a broad class of unsupervised, supervised, and reinforcement machine learning algorithms which iteratively update their parameter vector by adding a perturbation based upon all of the training data. This process is repeated, making a perturbation of the parameter vector based upon all of the training data until a parameter vector is generated which exhibits improved predictive performance. The magnitude of the perturbation at each learning iteration is called the “stepsize” or “learning rate” and the identity of the perturbation vector is called the “search direction”. Simple mathematical formulas are presented based upon research from the late 1960s by Philip Wolfe and G. Zoutendijk that ensure convergence of the generated sequence of parameter vectors. These formulas may be used as the basis for the design of artificially intelligent smart automatic learning rate selection algorithms. The material in this podcast is designed to provide an overview of Chapter 7 of my new book “Statistical Machine Learning” and is based upon material originally presented in Episode 68 of Learning Machines 101!
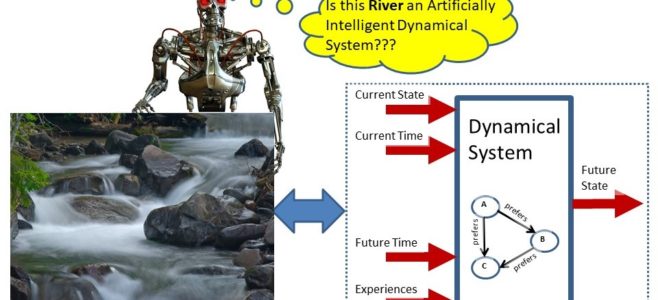
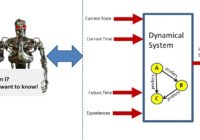
Episode Summary: In this episode of Learning Machines 101, we review Chapter 6 of my book “Statistical Machine Learning” which introduces methods for analyzing the behavior of machine inference algorithms and machine learning algorithms as dynamical systems. We show that when dynamical systems can be viewed as special types of optimization algorithms, the behavior of those systems even… Read More »
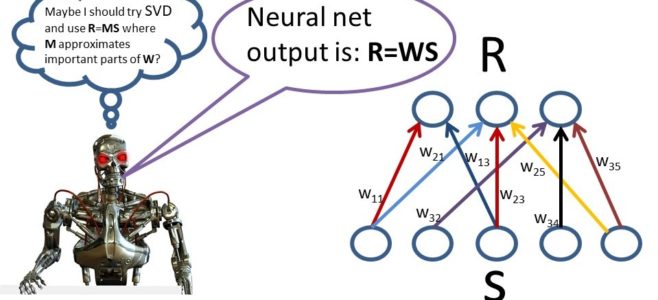
Episode Summary: This particular podcast covers the material from Chapter 5 of my new book “Statistical Machine Learning: A unified framework” which is now available! The book chapter shows how matrix calculus is very useful for the analysis and design of both linear and nonlinear learning machines with lots of examples. Show Notes: Hello everyone! Welcome to the… Read More »
Episode Summary: This particular podcast covers the material in Chapter 4 of my new book “Statistical Machine Learning: A unified framework” which is now available! Many important and widely used machine learning algorithms may be interpreted as linear machines and this chapter shows how to use linear algebra to analyze and design such machines. In addition, these same… Read More »
A large class of complex machine learning algorithms can be represented as dynamical systems which are minimizing an objective function with respect to a preference relation.
Episode Summary: This particular podcast covers the material in Chapter 2 of my new book “Statistical Machine Learning: A unified framework” with expected publication date May 2020. In this episode we discuss Chapter 2 of my new book, which discusses how to represent knowledge using set theory notation. Chapter 2 is titled “Set Theory for Concept Modeling”. Show… Read More »
Episode Summary: This particular podcast covers the material in Chapter 1 of my new (unpublished) book “Statistical Machine Learning: A unified framework”. In this episode we discuss Chapter 1 of my new book, which shows how supervised, unsupervised, and reinforcement learning algorithms can be viewed as special cases of a general empirical risk minimization framework. This is useful… Read More »
This particular podcast is the initial episode in a new special series of episodes designed to provide commentary on a new book that I am in the process of writing. In this episode we discuss books, software, courses, and podcasts designed to help you become a machine learning expert!
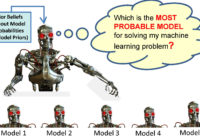
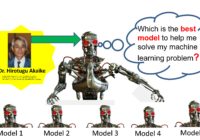
Episode Summary: In this episode, we explain the proper semantic interpretation of the Bayesian Information Criterion (BIC) and emphasize how this semantic interpretation is fundamentally different from AIC (Akaike Information Criterion) model selection methods. Briefly, BIC is used to estimate the probability of the training data given the probability model, while AIC is used to estimate out-of-sample prediction… Read More »
Episode Summary: In this episode, we explain the proper semantic interpretation of the Akaike Information Criterion (AIC) and the Generalized Akaike Information Criterion (GAIC) for the purpose of picking the best model for a given set of training data. The precise semantic interpretation of these model selection criteria is provided, explicit assumptions are provided for the AIC and… Read More »
LM101-075: Can computers think? A Mathematician’s Response using a Turing Machine Argument (remix) Episode Summary: In this episode, we explore the question of what can computers do as well as what computers can’t do using the Turing Machine argument. Specifically, we discuss the computational limits of computers and raise the question of whether such limits pertain to biological… Read More »
LM101-074: How to Represent Knowledge using Logical Rules (remix) Episode Summary: In this episode we will learn how to use “rules” to represent knowledge. We discuss how this works in practice and we explain how these ideas are implemented in a special architecture called the production system. The challenges of representing knowledge using rules are also discussed. Specifically,… Read More »
LM101-073: How to Build a Machine that Learns Checkers (remix) Episode Summary: This is a remix of the original second episode Learning Machines 101 which describes in a little more detail how the computer program that Arthur Samuel developed in 1959 learned to play checkers by itself without human intervention using a mixture of classical artificial intelligence search… Read More »
LM101-072: Welcome to the Big Artificial Intelligence Magic Show! (LM101-001+LM101-002 remix) Episode Summary: This podcast is basically a remix of the first and second episodes of Learning Machines 101 and is intended to serve as the new introduction to the Learning Machines 101 podcast series. The search for common organizing principles which could support the foundations of machine… Read More »
LM101-071: How to Model Common Sense Knowledge using First-Order Logic and Markov Logic Nets Episode Summary: In this podcast, we provide some insights into the complexity of common sense. First, we discuss the importance of building common sense into learning machines. Second, we discuss how first-order logic can be used to represent common sense knowledge. Third, we describe… Read More »
LM101-070: How to Identify Facial Emotion Expressions in Images Using Stochastic Neighborhood Embedding Episode Summary: This 70th episode of Learning Machines 101 we discuss how to identify facial emotion expressions in images using an advanced clustering technique called Stochastic Neighborhood Embedding. We discuss the concept of recognizing facial emotions in images including applications to problems such as: improving… Read More »
LM101-069: What Happened at the 2017 Neural Information Processing Systems Conference? Episode Summary: This 69th episode of Learning Machines 101 provides a short overview of the 2017 Neural Information Processing Systems conference with a focus on the development of methods for teaching learning machines rather than simply training them on examples. In addition, a book review of… Read More »
LM101-068: How to Design Automatic Learning Rate Selection for Gradient Descent Type Machine Learning Algorithms Episode Summary: This 68th episode of Learning Machines 101 discusses a broad class of unsupervised, supervised, and reinforcement machine learning algorithms which iteratively update their parameter vector by adding a perturbation based upon all of the training data. This process is repeated, making… Read More »
LM101-067: How to use Expectation Maximization to Learn Constraint Satisfaction Solutions (Rerun) Episode Summary: In this episode we discuss how to learn to solve constraint satisfaction inference problems. The goal of the inference process is to infer the most probable values for unobservable variables. These constraints, however, can be learned from experience. Specifically, the important machine learning method… Read More »
LM101-066: How to Solve Constraint Satisfaction Problems using MCMC Methods (Rerun) Episode Summary: In this episode we discuss how to solve constraint satisfaction inference problems where knowledge is represented as a large unordered collection of complicated probabilistic constraints among a collection of variables. The goal of the inference process is to infer the most probable values of the… Read More »
LM101-065: How to Design Gradient Descent Learning Machines (Rerun) Episode Summary: In this episode we introduce the concept of gradient descent which is the fundamental principle underlying learning in the majority of deep learning and neural network learning algorithms. Show Notes: Hello everyone! Welcome to the sixteenth podcast in the podcast series Learning Machines 101. In this series… Read More »
LM101-064: Stochastic Model Search and Selection with Genetic Algorithms (Rerun) Episode Summary: In this episode we explore the concept of evolutionary learning machines. That is, learning machines that reproduce themselves in the hopes of evolving into more intelligent and smarter learning machines. This is a rerun of Episode 24. Show Notes: Hello everyone! Welcome to the twenty-fourth podcast in… Read More »
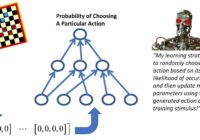
LM101-063: How to Transform a Supervised Learning Machine into a Policy Gradient Reinforcement Learning Machine Episode Summary: This 63rd episode of Learning Machines 101 discusses how to build reinforcement learning machines which become smarter with experience but do not use this acquired knowledge to modify their actions and behaviors. This episode explains how to build reinforcement learning machines… Read More »
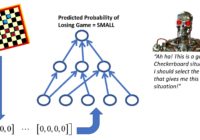
LM101-062: How to Transform a Supervised Learning Machine into a Value Function Reinforcement Learning Machine Episode Summary: This 62nd episode of Learning Machines 101 discusses how to design reinforcement learning machines using your knowledge of how to build supervised learning machines! Specifically, we focus on Value Function Reinforcement Learning Machines which estimate the unobservable total penalty associated with… Read More »
LM101-061: What happened at the Reinforcement Learning Tutorial? (RERUN) Episode Summary: This is the third of a short subsequence of podcasts providing a summary of events associated with Dr. Golden’s recent visit to the 2015 Neural Information Processing Systems Conference. This is one of the top conferences in the field of Machine Learning. This episode reviews and discusses… Read More »
LM101-060: How to Monitor Machine Learning Algorithms using Anomaly Detection Machine Learning Algorithms Episode Summary: This 60th episode of Learning Machines 101 discusses how one can use novelty detection or anomaly detection machine learning algorithms to monitor the performance of other machine learning algorithms deployed in real world environments. The episode is based upon a review of a… Read More »
LM101-059: How to Properly Introduce a Neural Network Episode Summary: I discuss the concept of a “neural network” by providing some examples of recent successes in neural network machine learning algorithms and providing a historical perspective on the evolution of the neural network concept from its biological origins. Show Notes: Hello everyone! Welcome to the fifty-ninth podcast in… Read More »
LM101-058: How to Identify Hallucinating Learning Machines using Specification Analysis Episode Summary: In this 58th episode of Learning Machines 101, I’ll be discussing an important new scientific breakthrough published just last week for the first time in the journal Econometrics in the special issue on model misspecification titled “Generalized Information Matrix Tests for Detecting Model Misspecification”. The article… Read More »
LM101-057: How to Catch Spammers using Spectral Clustering Episode Summary: In this 57th episode, we explain how to use spectral cluster analysis unsupervised machine learning algorithms to catch internet criminals who try to steal your money electronically! Show Notes: Hello everyone! Welcome to the fifty-seventh podcast in the podcast series Learning Machines 101. In this series of podcasts… Read More »
LM101-056: How to Build Generative Latent Probabilistic Topic Models for Search Engine and Recommender System Applications Episode Summary: In this episode we discuss Latent Semantic Indexing type machine learning algorithms which have a probabilistic interpretation. We explain why such a probabilistic interpretation is important and discuss how such algorithms can be used in the design of document retrieval… Read More »
LM101-055: How to Learn Statistical Regularities using MAP and ML Estimation Episode Summary: In this rerun of Episode 10, we discuss fundamental principles of learning in statistical environments including the design of learning machines that can use prior knowledge to facilitate and guide the learning of statistical regularities. Show Notes: Hello everyone! Welcome to the tenth podcast in… Read More »
LM101-054: How to Build Search Engine and Recommender Systems using Latent Semantic Analysis (RERUN) Episode Summary: In this episode we explain how to build a search engine, automatically grade essays, and identify synonyms using Latent Semantic Analysis. Preamble: Welcome to the 54th Episode of Learning Machines 101 titled “How to Build a Search Engine, Automatically Grade Essays,… Read More »
LM101-053: How to Enhance Learning Machines with Swarm Intelligence (Particle Swarm Optimization) Episode Summary: In this 53rd episode of Learning Machines 101, we introduce the concept of a Swarm Intelligence with respect to Particle Swarm Optimization Algorithms. The essential idea of “Swarm Intelligence” is that you have a group of individual entities which behave in a coordinated manner… Read More »
LM101-052: How to Use the Kernel Trick to Make Hidden Units Disappear Episode Summary: Today, we discuss a simple yet powerful idea which began popular in the machine learning literature in the 1990s which is called “The Kernel Trick”. The basic idea behind “The Kernel Trick” is that an impossible machine learning problem can be transformed into an… Read More »
LM101-051: How to Use Radial Basis Function Perceptron Software for Supervised Learning [Rerun] Episode Summary: In this episode we describe how to download and use free nonlinear machine learning software for implementing a Perceptron learning machine with a single layer of Radial Basis Function hidden units for the purposes of supervised learning. Show Notes: Welcome to the 51st podcast… Read More »
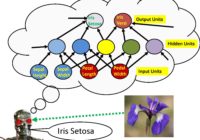
LM101-050: How to Use Linear Machine Learning Software to Make Predictions (Linear Regression Software)[RERUN] Episode Summary: In this episode we describe how to download and use free linear machine learning software to make predictions for classifying flower species using a famous machine learning data set. This is a RERUN of Episode 13. Show Notes: Hello everyone! Welcome to… Read More »
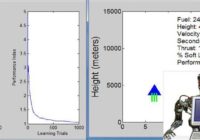
LM101-049: How to Experiment with Lunar Lander Software Episode Summary: In this episode we continue the discussion of learning when the actions of the learning machine can alter the characteristics of the learning machine’s statistical environment. We describe how to download free lunar lander software so you can experiment with an autopilot for a lunar lander module that… Read More »
LM101-048: How to Build a Lunar Lander Autopilot Learning Machine (Rerun) Episode Summary: In this episode we consider the problem of learning when the actions of the learning machine can alter the characteristics of the learning machine’s statistical environment. We illustrate the solution to this problem by designing an autopilot for a lunar lander module that learns from… Read More »
LM101-047: How To Build a Support Vector Machine to Classify Patterns (Rerun) Episode Summary: In this RERUN of the 32nd episode of Learning Machines 101, we introduce the concept of a Support Vector Machine. We explain how to estimate the parameters of such machines to classify a pattern vector as a member of one of two categories… Read More »
LM101-046: How to Optimize Student Learning using Recurrent Neural Networks (Educational Technology) Episode Summary: In this episode, we briefly review Item Response Theory and Bayesian Network Theory methods for the assessment and optimization of student learning and then describe a poster presented on the first day of the Neural Information Processing Systems conference in December 2015 in Montreal… Read More »
LM101-045: How to Build a Deep Learning Machine for Answering Questions about Images Episode Summary: This is the fourth of a short subsequence of podcasts which provides a summary of events associated with Dr. Golden’s recent visit to the 2015 Neural Information Processing Systems Conference. This is one of the top conferences in the field of Machine Learning. This… Read More »
LM101-044: What happened at the Deep Reinforcement Learning Tutorial at the 2015 Neural Information Processing Systems Conference? Episode Summary: This is the third of a short subsequence of podcasts providing a summary of events associated with Dr. Golden’s recent visit to the 2015 Neural Information Processing Systems Conference. This is one of the top conferences in the field… Read More »
LM101-043: How to Learn a Monte Carlo Markov Chain to Solve Constraint Satisfaction Problems (Rerun of Episode 22) Welcome to the 43rd Episode of Learning Machines 101! We are currently presenting a subsequence of episodes covering the events of the recent Neural Information Processing Systems Conference. However, this week will digress with a rerun of Episode 22 which… Read More »
LM101-042: What happened at the Monte Carlo Inference Methods Tutorial at the 2015 Neural Information Processing Systems Conference? Episode Summary: This is the second of a short subsequence of podcasts providing a summary of events associated with Dr. Golden’s recent visit to the 2015 Neural Information Processing Systems Conference. This is one of the top conferences in the… Read More »
LM101-041: What happened at the 2015 Neural Information Processing Systems Deep Learning Tutorial? Episode Summary: This is the first of a short subsequence of podcasts which provides a summary of events at the recent 2015 Neural Information Processing Systems Conference. This is one of the top conferences in the field of Machine Learning. This episode introduces the Neural… Read More »
LM101-040: How to Build a Search Engine, Automatically Grade Essays, and Identify Synonyms using Latent Semantic Analysis Episode Summary: In this episode we explain how to build a search engine, automatically grade essays, and identify synonyms using Latent Semantic Analysis. Show Notes: Hello everyone! Welcome to the fortieth podcast in the podcast series Learning Machines 101. In this… Read More »
LM101-039: How to Solve Large Complex Constraint Satisfaction Problems (Monte Carlo Markov Chain) Episode Summary: In this episode we discuss how to solve constraint satisfaction inference problems where knowledge is represented as a large unordered collection of complicated probabilistic constraints among a collection of variables. The goal of the inference process is to infer the most probable values… Read More »
LM101-038: How to Model Knowledge Skill Growth Over Time using Bayesian Nets Episode Summary: In this episode, we examine the problem of developing an advanced artificially intelligent technology which is capable of tracking knowledge growth in students in real-time, representing the knowledge state of a student a skill profile, and automatically defining the concept of a skill without… Read More »
LM101-037: How to Build a Smart Computerized Adaptive Testing Machine using Item Response Theory Episode Summary: In this episode, we discuss the problem of how to build a smart computerized adaptive testing machine using Item Response Theory (IRT). Suppose that you are teaching a student a particular target set of knowledge. Examples of such situations obviously occur in… Read More »