Podcast: Play in new window | Download | Embed
LM101-069: What Happened at the 2017 Neural Information Processing Systems Conference?
Episode Summary:
This 69th episode of Learning Machines 101 provides a short overview of the 2017 Neural Information Processing Systems conference with a focus on the development of methods for teaching learning machines rather than simply training them on examples. In addition, a book review of the book “Deep Learning” is provided.
Show Notes:
Hello everyone! Welcome to the 69th podcast in the podcast series Learning Machines 101. In this series of podcasts my goal is to discuss important concepts of artificial intelligence and machine learning in hopefully an entertaining and educational manner.
In this podcast, we will have a brief review of the events at the recent 2017 Neural Information Processing Systems (NIPS) Conference. Historically, the birth of the NIPS began at the Snowbird Conference on Neural Networks for Computing which was an invitation-only conference for not only artificial intelligence researchers interested in building smart machines but also computational biologists interested in modeling biological brains. In 1986, the amount of research generated in this area had been expanding at a rapid rate and the Snowbird Group decided to create a new public conference on these topics.
I attended the first NIPS conference was held in 1987. The paper I presented at this conference was titled “Probabilistic Characterization of Neural Model Computations” which argued that many popular artificial neural network models could be viewed as statistical pattern recognition algorithms. I discussed how a multi-layer perceptron architecture (known as an associative back-propagation network) could be formally viewed as a nonlinear regression model with additive Gaussian noise. I also discussed how the deterministic two-state Hopfield (1982) model and the deterministic continuous state Brain-State-in-a-Box neural network model could be interpreted as seeking “most probable’’ responses with respect to a particular probability mass function which was quite different from a nonlinear regression model. Next, I noted that one could analyze and design learning algorithms using the probabilistic representations one had defined for these models through gradient descent on their negative log-likelihood functions. And finally, I briefly commented that by explicitly specifying the semantics of an artificial neural network model, one could develop methods for checking for model misspecification. Since 1987, my first two points have been widely accepted by the NIPS community. Indeed, today they are considered “obvious’’ but in 1987 these ideas were not new but they certainly were not widely appreciated. The third point regarding model misspecification has been generally ignored despite the fact it is an equally important point. I’ve recently published a paper on this topic and the link to that paper as well as my NIPS paper at the first NIPS conference can be found in the show notes of this episode. It is my recollection that there were only about 150 people at the first NIPS conference. There were about 100 papers published in the first NIPS proceedings.
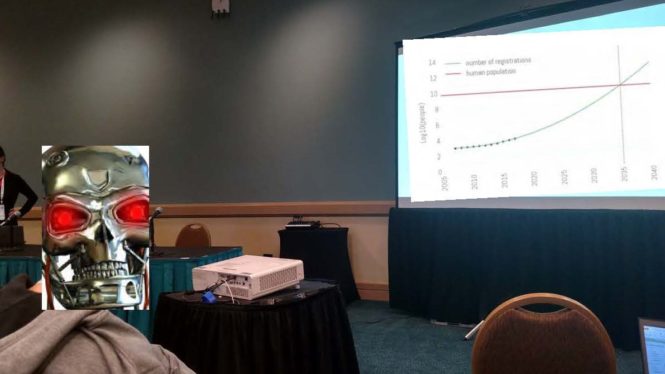
Now fast-forward through the decades to NIPS 2017. Early registration for this conference began I believe around October 1, 2017. I registered for the conference within the first two weeks of the registration deadline. Before November 1, 2017 the entire conference had sold out! This is pretty amazing! We are not talking about some popular rock concert! We are talking about a scientific conference whose talks are aimed at a select group of researchers with advanced expertise in machine learning! The total number of people that ultimately attended the conference was approximately 8,000 registrants which is a lot more than 150 scientists and engineers! In addition, representatives from Facebook, Baidu, Google, DeepMind, Capital One, Nvidia, Amazon, Uber, Apple, Salesforce, Adobe, JP Morgan, and many other companies were present describing how they have applied machine learning technologies and attempting to recruit new talent! Indeed, someone plotted the expected growth of participation in the NIPS conference and found that at the current growth rate that by the year 2035 the number of attendees at the NIPS conference will exceed the entire population of the planet Earth! So I guess after the year 2035, we will probably have to start meeting on a larger planet!
The conference began with a day of Tutorials. I attended the Reinforcement Learning with People Tutorial presented by Emma Brunskill in the morning. The tutorial began with a review of basic concepts of reinforcement learning. Reinforcement learning, as discussed in Episodes 44, 61, 62, and 63, involves receiving partial feedback from the environment over time about rewards to be received in the future. This stands in contrast to unsupervised learning where the learning machine observes events in its environment without feedback regarding the appropriate response and supervised learning where the learning machine receives feedback regarding the appropriate response for a given event. The terminology “deep reinforcement learning” refers to the idea that we have a situation involving reinforcement learning where the learning machine actively constructs and creates novel features of its statistical environment to exploit.
Dr. Brunskill from Stanford University noted that although there have been important advances in deep reinforcement learning in both games and robotics, reinforcement learning can be quite challenging in complex environments where there are many possible informational cues and different subsets of these cues will be relevant or irrelevant in different tasks. In many of these environments, the information received by the learning machine is generated by people. This means that performance of our learning machines might improve in some cases if we can teach people how to interact with learning machines. A critical point made by Dr. Brunskill which she also discussed zt the Teaching Machines, Robots, and Humans workshop at the conference is that “we don’t want to replace people with AI” we want “AI and people to work together”. Dr. Brunskill notes that deep reinforcement systems are now being applying to develop optimal personalized learning instruction where the reinforcement learning system’s action involves presenting the right homework problem or exam question to a student at just the right time to ensure that the student successfully passes a final exam at the end of a course. Another example is a system which provides information to a human over a period of time in such a way so that the human eventually buys a product. And a third example, is a “self-driving car” which needs to interact with both the human which is driving the car and the other humans which are on the road who are also driving cars in order to eventually bring the human driver safely to his or her destination.
A standard topic at most machine learning conferences intended to achieve such goals is how can the algorithm be improved? And this question, of course, is critically important and can always benefit from further investigation. However, a crucial question which is perhaps equally important is how can the process of “teaching” the algorithm be improved?
This is a critical idea which has been in the machine learning literature for many years. The essential idea is that one should first learn a simplified caricature of a task. Once that is acquired, then that provides the framework for learning the details of the task which incorporate the task’s full complexity. This approach is in stark contrast to the typical perspective presented for training reinforcement learning machines which essentially says: “provide enough examples of what you want the learning machine to do” and it will eventually learn to do the task. That is, “Doing a task is different from teaching a task”.
Suppose you are teaching a student a complex task such as riding a bicycle, catching a football, or hitting the perfect racquetball stroke. A good instructor won’t simply demonstrate an “expert” version of these tasks but rather will additionally demonstrate a “simplified caricature” of these tasks intended to help the learner focus on specific points of the task which might not be appreciated. For example, additional power in a racquetball stroke can be generated by rotating the waist, stepping forward as the ball is contacted, leading with the elbow, and letting your body momentum generate a strong wrist snap. A novice watching a world class racquetball player hit a perfect forehand racquetball stroke is likely not to realize or appreciate these specific components. Learning will often be faster and more effective if the student observes the full complete “expert” version of the task as well as the “simplified caricature” of the task. Different teaching methods might emphasize one of these two approaches more than another or argue that one task such as the “simplified caricature” should be learned before the “expert version”.
From the perspective of nonlinear optimization theory, the idea of developing methods for teaching learning systems corresponds to the idea that in order to find a good local minimizer of a complicated objective function using gradient descent, it is important to have a good initial guess for that minimizer which is “close” to that minimizer. To find that good initial guess, one might design a simplified objective function which has fewer minima and is even possibly convex and use that to estimate the initial guess. Then that initial guess can be used as a starting point for a gradient descent algorithm which operates on the original complicated nonlinear objective function.
To summarize, the key idea which has been empirically supported not only by talks at this conference but prior published research in the area is that we may be able to dramatically improve the efficiency of learning in learning machines if we present our learning machines with carefully crafted curricula. Training them with simplified statistical environments in order to obtain initial parameter estimates, and then using those initial parameter estimates as a starting point for learning more complicated statistical environments.
After the Monday Tutorial day, the main conference was held on Tuesday, Wednesday, and Thursday and consisted of continuous sessions beginning each day at 8am and ending around 5pm with poster sessions from 6pm onwards into the evening. Following the main conference, there were two days of conference workshops. I took numerous notes so I’ve got lots of material for future podcasts on topics which were covered! One workshop in particular discussed issues which I feel have not been sufficiently addressed by the machine learning community. The title of that workshop was “Transparency and Interpretable Machine Learning in Safety Critical Environments”. The basic idea, here, is that in many safety-critical applications it is not sufficient to have good predictions from our machine learning algorithms we need the algorithms to also provide us with good explanations of their predictions and we need to be convinced that the way the machines are arriving at their predictions is rational and appropriate. For example, if a machine learning algorithm decided to deny your health insurance request or financial loan request and therefore consequently condemning your family to excessive hardships for the rest of their lives, you would think that the machine learning algorithm would be obligated to explain the logic behind its decision making process! I definitely want to devote any entire podcast to this topic! Too much material, however, to discuss today!
At this point, I would like to introduce a relatively new feature to this podcast which is my review of a recent book in the area of Machine Learning. I think this will be helpful to listeners because some of the books in this area are very introductory, some are very advanced, some focus on more theoretical issues, while others focus on more practical issues. These book reviews should be helpful because I will try to discuss the general contents of books which I think are especially relevant and additionally will make some comments regarding who might be interested in these books and who might not be interested.
I’m beginning this new component of my podcast with a review of the book “Deep Learning” which appeared in print in November 2016.
If you are interested in implementing Deep Learning algorithms, then you must get this book! This is the currently the best documentation on basic principles of Deep Learning Algorithms that exists! It is written by Dr. Ian Goodfellow, Dr. Yoshua Bengio, and Dr. Aaron Courville who are three experts in the field with considerably theoretical and empirical experience with Deep Learning algorithms.
Chapters 1, 2, 3, 4 provide a background on Deep Learning, Linear Algebra, Probability Theory, and Iterative Deterministic Optimization algorithms. Chapter 5 is a basic introduction to Machine Learning algorithms which covers topics such as the importance of having a training and test data set, hyperparameters, maximum likelihood estimation, maximum a posteriori (MAP) estimation, and stochastic gradient descent algorithms. Chapter 6 introduces feedforward multilayer perceptrons, different types of hidden units as well as different types of output unit representations corresponding to different types of probabilistic modeling assumptions regarding the distribution of the target given the input pattern. Chapter 6 also discusses the concept of differentiation algorithms using computational graphs. The computational graph methodology is extremely powerful for the derivation of derivatives of objective functions for complicated network architectures. Chapter 7 discusses the all-important concept of regularization. In the mid-1980s, the guiding philosophy was to start with smaller more simpler network architectures and “grow’’ those architectures. Later on, however, in the early 21st century it was found that for certain types of various complicated problems that a much more effective approach was to start with a very complicated network architecture and “shrink” that architecture without sacrificing predictive performance. The basic underlying idea is that rather than find the parameters of the learning machine which merely reduce the learning machine’s predictive error, the learning rule is designed to minimize an objective function which takes on large values when either the predictive error is large or when the learning machine has an excessive number of free parameters. Thus, the learning machine essentially “designs itself’’ during the learning process! This type of methodology is called “regularization’’. The standard L1 regularization (penalize if the sum of the absolute values of the parameter values are large) and the standard L2 regularization (penalize if the sum of the squares of the parameter values are large). Adversarial training is also introduced as a regularization technique. Chapter 8 introduces optimization methods for training deep learning network architectures. Such methods include: batch, minibatch, stochastic gradient descent (SGD), SGD with momentum, parameter initialization strategies, ADAgrad, RMSprop and their variants, Limited Memory BFGS algorithms, updating groups of parameters at a time (block coordinate descent), averaging the last few parameter estimates in an on-line adaptive learning algorithm to improve the estimate (Polyak Averaging), supervised pretraining, continuation methods and curriculum learning. Anyone who is using a deep learning algorithm should be familiar with all of these methods and when they are applicable because these different techniques were specifically designed to commonly encountered problems in specific deep learning applications. Chapter 9 discusses convolutional neural networks. Analogous to the convolution operator in the time domain, a convolutional neural network implements a convolution operator in the spatial domain. The basic idea of the convolutional neural network is that one applies a collection of spatial convolution operators which have free parameters to the image which process very small regions of an image. The output of this collection of spatial convolution operators then forms the input pattern for the next layer of spatial convolution operators which are looking for statistical regularities in the outputs of the first layer. Chapter 10 discusses the concept of recurrent and recursive neural networks and how to derive learning algorithms for them using computational graphs. Chapter 11 provides a guide for a practical methodology for applying deep learning methods. Chapter 12 discusses applications in the areas of: computer vision, speech recognition, natural language processing, machine translation, recommender systems. The remaining third of the book constitutes Part 3 which includes a discussion of important topics in deep learning which are active research topics.
So who should consider reading this book? The book is relatively self-contained with relevant reviews of linear algebra, probability theory, and numerical optimization. Although some prior background in linear algebra, calculus, probability theory, and machine learning is helpful, readers without this background should still find the book reasonably accessible but may struggle a bit with sections in the text involving mathematical notation for the purposes of making specific arguments or specifying specific algorithms.
One nice thing about this book is that it is free! You can go to: www.deeplearningbook.org and read the entire book for free but you can’t download a copy. Or, you can purchase a hard copy or electronic copy for $80. You can also support this podcast by visiting my website: www.learningmachines101.com and click on Book Reviews on the main menu and then order the book by clicking on the relevant Book Review and then visiting the Amazon website via my web-page. I receive a small commission on such book purchases from Amazon which does not add to the cost of your book. The money I receive is invested directly into the dissemination of future episodes of Learning Machines 101.
Thank you again for listening to this episode of Learning Machines 101! I would like to remind you also that if you are a member of the Learning Machines 101 community, please update your user profile and let me know what topics you would like me to cover in this podcast.
You can update your user profile when you receive the email newsletter by simply clicking on the: “Let us know what you want to hear” link!
If you are not a member of the Learning Machines 101 community, you can join the community by visiting our website at: www.learningmachines101.com and you will have the opportunity to update your user profile at that time. You can also post requests for specific topics or comments about the show in the Statistical Machine Learning Forum on Linked In.
From time to time, I will review the profiles of members of the Learning Machines 101 community and comments posted in the Statistical Machine Learning Forum on Linked In and do my best to talk about topics of interest to the members of this group!
And don’t forget to follow us on TWITTER. The twitter handle for Learning Machines 101 is “lm101talk”!
Also please visit us on ITUNES and leave a review. You can do this by going to the website: www.learningmachines101.com and then clicking on the ITUNES icon. This will be very helpful to this podcast! Thank you so much. Your feedback and encouragement are greatly valued!
Keywords: Neural Information Processing Systems, NIPS, Deep Learning, Shaping, Reinforcement Learning
Further Reading:
Golden, R. M. (1988). A Unified Framework for Connectionist Systems.
https://en.wikipedia.org/wiki/Conference_on_Neural_Information_Processing_Systems
https://papers.nips.cc/paper/75-probabilistic-characterization-of-neural-model-computations.pdf
https://www.learningmachines101.com/book-review-deep-learning/
Golden, R. M., Henley, S. S., White, H., and Kashner, T. M. (2016). Generalized Information Matrix Tests for Detecting Model Misspecification. Econometrics, 46.
http://www.mdpi.com/2225-1146/4/4/46 (this is a free open-access article!)
Golden, R. M., Henley, S. S., White, H., and Kashner, T. M. (2013). New Directions in Information Matrix Testing: Eigenspectrum Tests. In Recent Advances and Future Directions in Causality, Prediction, and Specification Analysis Edited By X. Chen and N. R. Swanson
www.springer.com/us/book/9781461416524
https://www.learningmachines101.com/lm101-061-happened-reinforcement-learning-tutorial-rerun/
https://nips.cc/Conferences/2017/Schedule?type=Tutorial
Copyright © 2017 by Richard M. Golden. All rights reserved.
